A. Intro
Pull the code for lab 19 and create a new project out of it.
B. The Abstract Graph
Linked lists ⊆ Trees ⊆ Graphs
One of the first data structures we studied in this course was the linked list, which consisted of a set of nodes connected in sequence. Then we looked at trees, which were a generalized version of linked lists: you could consider a tree as a linked list if you relaxed the constraint that a node could only have one child. Now we'll look at a generalization of a tree, called a graph, which can be considered a generalization of a tree if you relaxed the constraint that you can't have loops within the tree.
In a graph, we still have a collection of nodes, but each node in a graph can be connected to any other node without limitation. This means there isn't necessarily a hierarchical structure like you get in a tree. For example, here's a tree, where every node is descendent from one another:
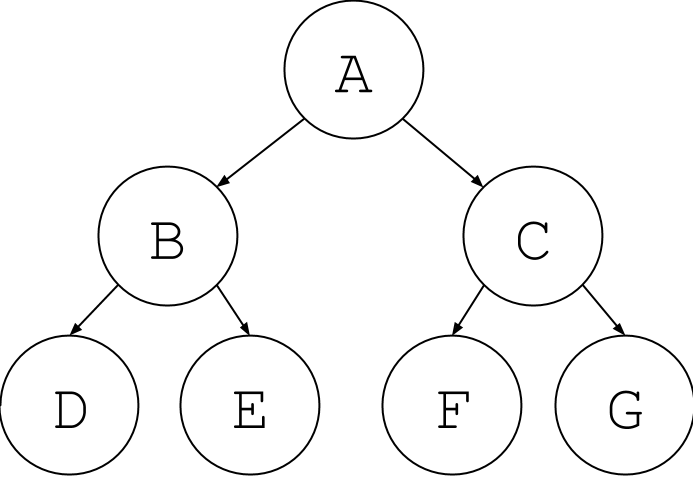
Now suppose you add an edge back up the tree. This is no longer a tree (notice the hierarchical structure is broken -- is C descendent from A or is A descendent from C?), but it is still a graph!
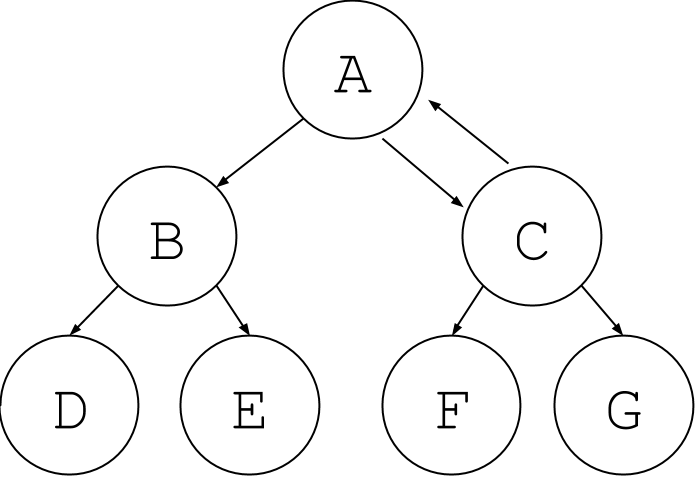
There are other edges that are not allowed in a tree. For example, now node E looks like it is descendent from two nodes. Again this is no longer a tree, but it is a graph.
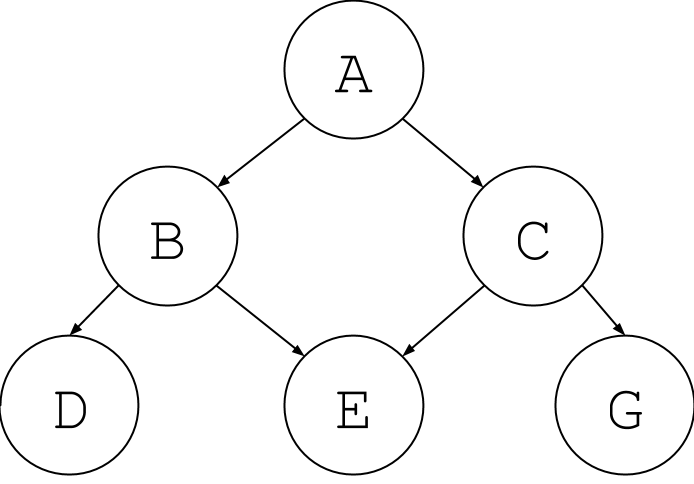
In general a graph can have any possible connection between nodes:
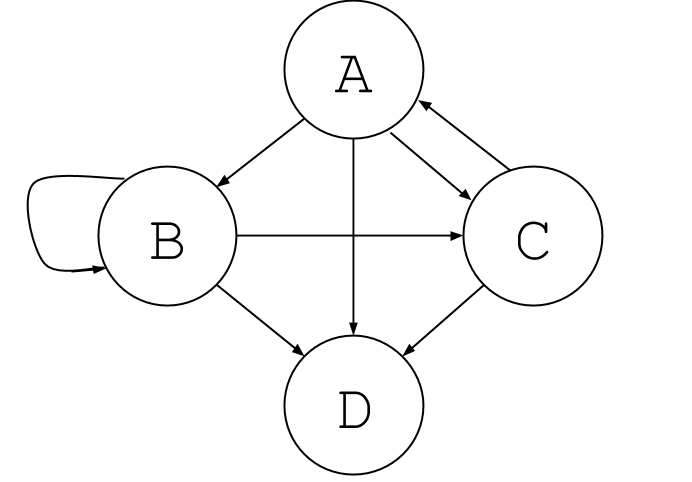
Overview of Graphs
First, let's go over some terminology. An element in a graph is called a vertex (basically a node, but we typically don't call them nodes). Vertices usually represent the objects in our graph, namely the things that have the relationships such as people, places, or things. A connection between two vertices is called an edge. An edge represents some kind of relationship between two vertices.
Quite a few examples of graphs exist in the everyday world:
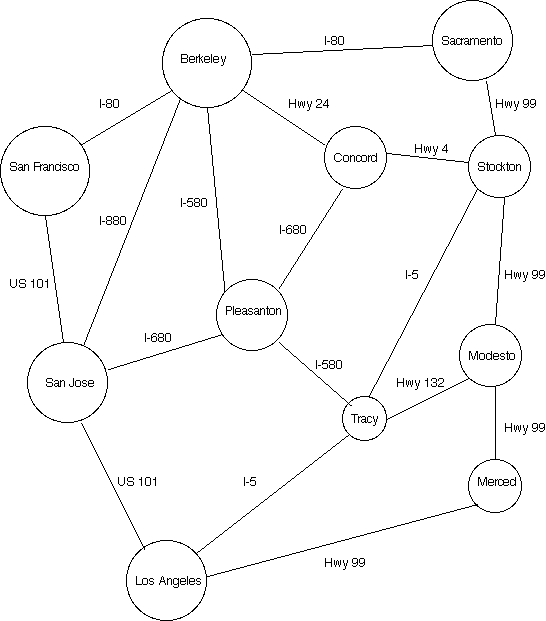
- Road maps are a great example of graphs. Each city is a vertex, and the edges that connect these cities are the roads and freeways. An abstract example of what such a graph would look like can be found here. For a more local example, each building on the Berkeley campus can be thought of as a vertex, and the paths that connect those buildings would be the edges.
- Facebook depends on graphs. Each person that participates is a vertex, and an edge is established when two people claim to be friends or associates of each other.
- For a more technical example, a computer network is also a graph. In this case, computers and other network machinery (like routers and switches) are the vertices, and the edges are the network cables. Or for a wireless network, an edge is an established connection between a single computer and a single wireless router.
{kind=link}
In more formal mathematical notation, a vertex is written as a variable, such as v0, v1, v2, etc. An edge is written as a pair of vertices, such as (v0, v1), or (v2, v0).
Directed vs. Undirected Graphs
Once again, an element in a graph is called a vertex, and a connection between two vertices is called an edge.
If all edges in a graph are showing a relationship between two vertices that works in either direction, then it is called an undirected graph. A picture of an undirected graph looks like this:
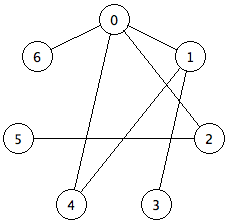
But not all edges in graphs are the same. Sometimes the relationships between two vertices sometimes only go in one direction. Such a relationship is called a directed graph. An example of this could be a city map, where the edges are sometimes one-way streets between locations. A two-way street would actually have to be represented as two edges, one of them going from location A to location B, and the other from location B to location A.
In terms of a visual representation of a graph, an undirected graph does not have arrows on its edges (because the edge connects the vertices in both directions), whereas each edge in a directed graph does have an arrow that points in the direction the edge is going. An example directed graph appears below.
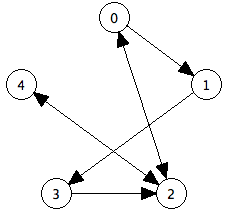
More formally, an edge from a vertex v0 to a vertex v1 is printed as the pair (v0, v1). In a directed graph, the pair is ordered; thus even if the edge (v0,v1) exists, (v1,v0) might not. In an undirected graph, the pair isn't ordered, so the edge (v0,v1) is the same as the edge (v1,v0).
Every undirected graph is a directed graph, but the converse is not true.
A Few More Graph Definitions
Now that we have the basics of what a graph is, here are a few more terms that might come in handy while discussing graphs.
| Term | Definition |
|---|---|
| Edge | A single connection between two vertices |
| Adjacent | Two vertices are adjacent if there is an edge connecting them |
| Connected | A graph is connected if every vertex has a path to all other vertices. (Also describes two nodes if there is an edge connecting them) |
| Neighbor | Two vertices are neighbors if there is an edge connecting them |
| Set of neighbors | The set of all nodes that are adjacent to/connected to/neighbors of a node |
| Incident to an edge | A vertex that is an endpoint of an edge is incident to it |
| Path | A sequence of edges that can be followed from one vertex to another, where no edge or vertex is repeated. |
| Cycle | A special kind of path that ends at the same vertex where it originally started |
Self-test: Edge Count vs. Vertex Count
Suppose that G is a directed graph with N vertices. What's the maximum number of edges that G can have? Assume that a vertex cannot have an edge pointing to itself, and that for each vertex u and vertex v, there is at most one edge (u,v).
|
N
|
Incorrect. Draw out a graph with 4 vertices. Can you find more than 4 edges between the nodes?
|
|
|
N^2
|
Incorrect. But it would be correct if a vertex can have an edge to itself, which is the case for some kinds of graphs.
|
|
|
N*(N-1)
|
Correct! Every vertex can be connected to every other vertex, of which there are N-1.
|
|
|
N*(N-1)/2
|
Incorrect. Remember the graph is
directed
.
|
Now suppose the same graph G in the above question is an undirected graph. Again assume that no vertex is adjacent to itself, and at most one edge connects any pair of vertices. What's the maximum number of edges that G can have?
|
half as many edges as in the directed graph
|
Correct! Remember the edges (u, v) and (v, u) now only count as one edge.
|
|
|
the same number of edges as in the directed graph
|
Incorrect. Remember the possible edges (u, v) and (v, u) now only count as one edge.
|
|
|
twice as many edges as in the directed graph
|
Incorrect. Remember the edges (u, v) and (v, u) now only count as one edge.
|
What's the minimum number of edges that a connected undirected graph with N vertices can have?
|
N-1
|
Correct! (In fact, an undirected connected graph with N-1 edges is a tree!)
|
|
|
N
|
Incorrect. Think of the small case. How many edges do you need to connect a graph with two nodes?
|
|
|
N^2
|
Incorrect. There aren't this many possible edges in an undirected graph.
|
|
|
N*(N-1)
|
Incorrect. There aren't this many possible edges in an undirected graph.
|
|
|
N*(N-1)/2
|
Incorrect. This is all possible edges in the graph! Surely we can do better.
|
Data Structures for Graphs
Now that we know how to draw a graph on paper and understand the basic concepts and definitions, we can consider how a graph should be represented inside of a computer. We want to be able to get quick answers for the following questions about a graph:
- Are given vertices
vandwadjacent? - Is vertex
vincident to a particular edgee? - What vertices are adjacent to
v? - What edges are incident to
v?
Most of today's lab will involve thinking about how fast and how efficient each of these operations is using different representations of a graph.
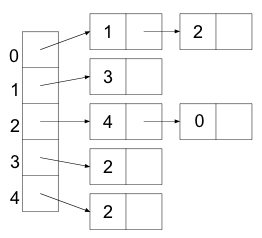
Imagine that we want to represent a graph that looks like this:
One data structure we could use to implement this graph is called an array of adjacency lists. In such a data structure, an array is created that has the same size as the number of vertices in the graph. Each position in the array represents one of the vertices in the graph. Each of these positions point to a list. These lists are called adjacency lists, as each element in the list represents a neighbor of the vertex.
The array of adjacency lists that represents the above graph looks like this:
Another data structure we could use to represent the edges in a graph is called an adjacency matrix. In this data structure, we have a two dimensional array of size nxn (where n is the number of vertices) which contains boolean values. The (i, j)th entry of this matrix is true when there is an edge from i to j and false when no edge exists. Thus, each vertex has a row and a column in the matrix, and the value in that table says true or false whether or not that edge exists.
The adjacency matrix that represents the above graph looks like this:
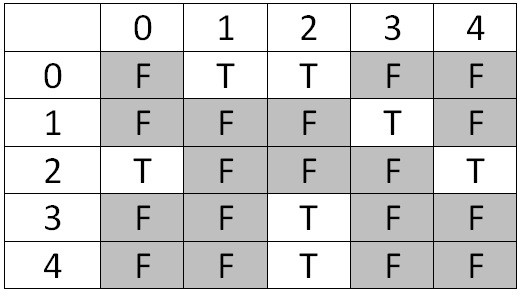
Consider what this matrix will look like for an undirected graph. You can imagine the matrix will be symmetric across its diagonal.
Discussion: Representing a Graph with a Linked Structure
A third data structure we could use to represent a graph (which you might have been already thinking of) is simply an extension of the linked nodes idea. We can just create a Vertex object for each vertex in the graph. Each of these objects will contain pointers to the Vertex objects of their neighbors. This may seem like the most straightforward approach: aren't the adjacency list and adjacency matrix roundabout in comparison?
Discuss reasons why the adjacency list or adjacency matrix might be preferred for a graph.
On the flipside, notice that we could also represent a tree using an ajacency matrix or list. Discuss reasons why an adjacency list or adjacency matrix might not be preferred for a tree.
Self-test: Which Data Structure is More Efficient?
Which is more efficient - an adjacency matrix or an array of adjacency lists?
|
Adjacency Matrix
|
Incorrect.
|
|
|
It depends
|
Correct! We'll explore why in the next few steps (besides, what does
efficient
even mean?).
|
|
|
Adjacency Lists
|
Incorrect.
|
Self-test: Graph Data Structure Trade-offs
Deciding how to store data is all about trade-offs. This quiz focuses on the BIG picture of which representation is more efficient in a given situation. The rest of the lab focuses on exactly how efficient things are.
Which is most SPACE efficient if you have a lot of edges in your graph?
|
Adjacency Matrix
|
Correct! Most of the spaces in the adjacency matrix will be used, so it won't be a waste.
|
|
|
Adjacency Lists
|
Incorrect. You'll have to store a lot of links if you have a lot of edges.
|
|
|
It depends
|
Incorrect. At a general level one of these data structures is more space efficient if we know the graph has a lot of edges.
|
Which is most SPACE efficient if you have very few edges in your graph?
|
Adjacency Matrix
|
Incorrect. No matter how many edges the graph has, you still have to store a whole matrix for all of them.
|
|
|
Adjacency Lists
|
Correct! You only have to store as many nodes in the adjacency list as there are edges. With an adjacency matrix, you have to store the full matrix regardless of how many edges you have.
|
|
|
It depends
|
Incorrect. At a general level one of these data structures is more space efficient if the know the graph has few edges.
|
Which is most TIME efficient for adding an edge if you have a lot of edges in your graph?
|
Adjacency Matrix
|
Correct! All we have to do to add an edge is index into the arrays and set a value to true.
|
|
|
Adjacency Lists
|
Incorrect. Adding a new edge requires creating a new node to append to our list of edges.
|
|
|
It depends
|
Incorrect.
|
|
|
They are the same
|
Incorrect. They can both be O(1) if you append to the front of the linked lists, but the amount of work you have to do for each is noticeably different.
|
Which is most TIME efficient for adding an edge if you have very few edges in your graph?
|
Adjacency Matrix
|
Correct! Adding an edge is the same no matter how many edges there are.
|
|
|
Adjacency Lists
|
Incorrect.
|
|
|
It depends
|
Incorrect.
|
|
|
They are the same
|
Incorrect.
|
Which is most TIME efficient for returning a list of edges from one node if you have very few edges in your graph?
|
Adjacency Matrix
|
Incorrect. You'll have to iterate through the whole array and check which values are true.
|
|
|
Adjacency Lists
|
Correct! This will be a lot faster if it just has a reference it can return to the neighbors of a node.
|
|
|
It depends
|
Incorrect.
|
|
|
They are the same
|
Incorrect.
|
Which is most TIME efficient for returning a list of edges from one node if you have a lot of edges in your graph?
|
Adjacency Matrix
|
Incorrect.
|
|
|
Adjacency Lists
|
Correct! For the same reason as before. Just returning a reference to the linked list does not change if there are more nodes in the list.
|
|
|
It depends
|
Incorrect.
|
|
|
They are the same
|
Incorrect.
|
Self-test: Time Estimates for Accessing Graph Information
Using an adjacency matrix, how long in the worst case does it take to determine if vertex v is adjacent to vertex w? (Assume vertices are represented by integers.)
|
constant time
|
Correct! All we have to do is index into the matrix at v and w and check if the value is true.
|
|
|
time proportional to the number of neighbors of vertex v
|
Incorrect. Remember the matrix is a 2D array, and we can index into any spot in it in constant time
|
|
|
time proportional to the number of vertices in the graph
|
Incorrect. Remember the matrix is a 2D array, and we can index into any spot in it in constant time
|
|
|
time proportional to the number of edges in the graph
|
Incorrect. Remember the matrix is a 2D array, and we can index into any spot in it in constant time
|
Using an array of adjacency lists, how long in the worst case does it take to determine if vertex v is adjacent to vertex w? (Assume vertices are represented by integers.)
|
constant time
|
Incorrect. Checking if list of neighbors contains a particular vertex requires iterating through it.
|
|
|
time proportional to the number of neighbors of vertex v
|
Correct. We have to iterate through all of them and check if any of them are w.
|
|
|
time proportional to the number of vertices in the graph
|
Incorrect. We only have to iterate through the list of neighbors of v.
|
|
|
time proportional to the number of edges in the graph
|
Incorrect. We only have to iterate through the list of neighbors of v.
|
Self-test: Memory Use in Adjacency Lists
Suppose we are representing a graph with N vertices and E edges.
There are N2 booleans stored in an adjacency matrix. Therefore the memory required to store an adjacency matrix is N2 times the memory required to store a boolean value. Assume that references and integers each use 1 unit of memory.
The amount of memory required to represent the graph as an array of adjacency lists is proportional to what?
|
N*E
|
Incorrect. Do we have all E edges stored for every node?
|
|
|
E*E
|
Incorrect.
|
|
|
N plus E
|
Correct! Look at the graph. There are N array elements and E nodes among the linked lists.
|
|
|
E
|
Incorrect. Don't forget about the references we have to store in the array elements.
|
C. Programs that Process Graphs
Graph Traversal
Earlier in the course, we used the general traversal algorithm to process all elements of a tree:
Stack fringe = new Stack();
fringe.push(myRoot);
while (!fringe.isEmpty()) {
// select a tree node from fringe
TreeNode node = fringe.pop();
// process the node
process(node);
// add node's children to fringe
fringe.push(node.myRight);
fringe.push(node.myLeft);
// Note: If this was a tree with more than
// two children, we'd push ALL of the
// children onto the stack.
}The code just given returns tree values in depth-first order. If we wanted a breadth-first traversal of a tree, we'd replace the Stack with a queue (the LinkedList class in java.util would be fine).
Think about how you can modify this algorithm to traverse a graph.
Analogous code to process every vertex in a connected graph may look something like:
Stack fringe = new Stack();
fringe.push(startVertex);
while (!fringe.isEmpty()) {
Vertex v = fringe.pop();
process(v); //do something with v
for (Vertex neighbor: v.neighbors) {
fringe.push(neighbor);
}
}This doesn't quite work, however. A graph may contain a cycle of vertices, and if that is the case here, the code loops infinitely.
The fix is to keep track of vertices that we've visited already (and put into the fringe), in order not to process them twice. Here is the correct pseudocode for graph traversal:
Stack fringe = new Stack();
Set visited = new Set();
fringe.push (startVertex);
while (!fringe.isEmpty()) {
Vertex v = fringe.pop();
if (!visited.contains(v)) {
process(v); //do something with v
for (Vertex neighbor: v.neighbors) {
fringe.push(neighbor);
}
visited.add(v);
}
}Note that the choice of data structure for the fringe can change. As with tree traversal, we can visit vertices in depth-first or breadth-first order merely by choosing a stack or a queue to represent the fringe. Typically though, because graphs are usually interconnected, the ordering of vertices can be scrambled up quite a bit. Thus, we don't worry too much about using a depth-first or a breadth-first traversal. Instead, in the next lab session we will see applications that use a priority queue to implement something more like best-first traversal.
Exercise Note: Keep in mind that, instead of checking that the popped vertex v is not yet visited, you can do this check before adding some neighbor to the fringe as well! This would look something like !visited.contains(neighbor). Although it is convention to check that the popped vertex is not yet visited, you may find this alternative way easier to code when you do the DFSIterator exercise later in the lab.
Exercise: Practice Graph Traversal
Use the graph traversal pseudocode from above to answer the following questions. It might help you to print out copies of the graph here. Now, figure out the order in which the nodes are visited if you start at different vertices. You can check your answers for starting at vertices 1 - 5 below.
For this problem assume that we add the vertex's unvisited edges to the stack in the order higher number to lower number.
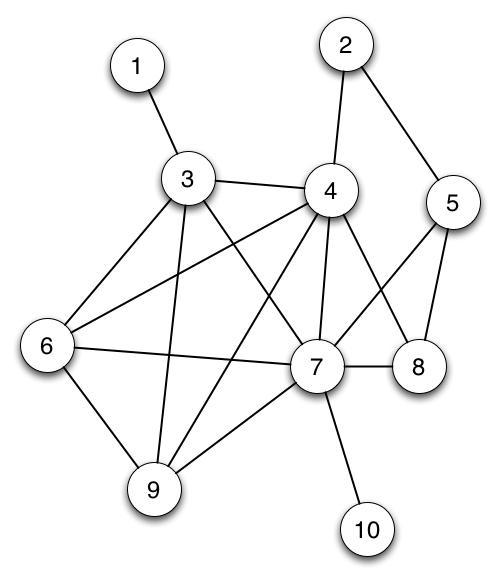

Answers for Practicing Graph Traversal
Here are the solutions for nodes 1-5 (just practice these until you feel comfortable).
| Starting vertex | Order of visiting remaining vertices |
|---|---|
| 1 | 3, 4, 2, 5, 7, 6, 9, 8, 10 |
| 2 | 4, 3, 1, 6, 7, 5, 8, 9, 10 |
| 3 | 1, 4, 2, 5, 7, 6, 9, 8, 10 |
| 4 | 2, 5, 7, 3, 1, 6, 9, 8, 10 |
| 5 | 2, 4, 3, 1, 6, 7, 8, 9, 10 |
Exercise: Graph.java
We have given you framework code for a class Graph. It implements a graph of Integers using an adjacency list.
Fill in some of the basic methods: addEdge, addUndirectedEdge, isAdjacent, neighbors, and inDegree.
Then complete the DFSIterator inner class. As its name suggests, it should iterate through all of the vertices in the graph in DFS order, starting from a vertex that is passed in as an argument.
Exercise: Using an Iterator to Find a Path, Part 1
First, switch which partner is coding for this lab if you haven't already.
Complete the method pathExists in Graph.java, which returns whether or not any path exists that goes from a vertex v to a vertex w. Remember that a path is any set of edges that exists which you can follow that such you travel from one vertex to another. You may find it helpful for your method to call the given method visitAll.
For an example of an undirected graph this should work on, try testing it with the following two graphs:
//Graph 1
addUndirectedEdge(0,2);
addUndirectedEdge(0,3);
addUndirectedEdge(1,4);
addUndirectedEdge(1,5);
addUndirectedEdge(2,3);
addUndirectedEdge(2,6);
addUndirectedEdge(4,5);
//Graph 2
addEdge(0,1);
addEdge(1,2);
addEdge(2,0);
addEdge(2,3);
addEdge(4,2); Exercise: Using an Iterator to Find a Path, Part 2
Now you will actually find a path from one vertex to another if it exists. Write code in the body of the method named path that, given two ints that represent a start vertex and a finish vertex, returns an ArrayList of Integers that represent vertices that lie on the path from the start to the finish. If no such path exists, you should return an empty ArrayList.
Algorithm hint: Pattern your method on visitAll, with the following differences. First, add code to stop calling next when you encounter the finish vertex. Then, trace back from the finish vertex to the start, by first finding a visited vertex u for which (u, finish) is an edge, then a vertex v visited earlier than u for which (v, u) is an edge, and so on, finally finding a vertex w for which (start, w) is an edge. Collecting all these vertices in the correct sequence produces the desired path. We recommend that you try this by hand with a graph or two to see that it works.
Topological Sort
A topological sort (sometimes also called a linearization) of a directed graph is a list of the vertices in such an order that if there is a directed path from vertex v to vertex w, then v precedes w in the list. More informally, topological sort returns a sequence of the vertices in the graph that doesn't violate the dependencies between any two vertices.
This only works on directed, acyclic graphs (can you imagine why?). Directed acyclic graphs are common enough to be referred to by their acronym: DAGs.
Here is an example of a DAG:
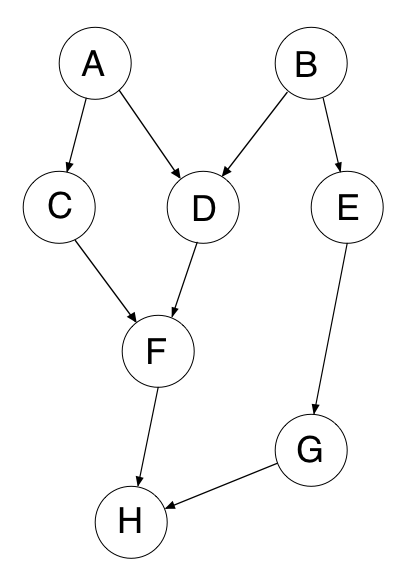
In the above DAG, a few of the possible topological sorts could be:
A B C D E F G H
A C B E G D F H
B E G A D C F HNotice that the topological sort for the above DAG has to start with either A or B, and must end with H. (For this reason, A and B are called sources, and H is called a sink.)
Another way to think about it is that the vertices in a DAG represent a bunch of tasks you need to complete on a to-do list. Some of those tasks cannot be completed until others are done. For example, when getting dressed in the morning, you may need to put on shoes and socks, but you can't just do them in any order. The socks must be put on before the shoes. Thus, a topological sort of your morning routing must have socks appear first before shoes.
The edges in the DAG represent dependencies between the tasks. In this example above, that would mean that task A must be completed before tasks C and D, task B must be completed before tasks D and E, E before G, C and D before F, and finally F and G before H. A topological sort gives you an order in which you can do the tasks (it puts the tasks in a linear order).
The Topological Sort Algorithm
The algorithm for taking a graph and finding a topological sort uses an array named currentInDegree with one element per vertex. currentInDegree[v] is initialized with the in-degree of each vertex v.
The algorithm also uses a fringe. The fringe is initialized with all vertices whose in-degree is 0. When a vertex is popped off the fringe and added to a results list, the currentInDegree value of its neighbors are reduced by 1. Then the fringe is updated again with vertices shows in-degree is now 0.
Exercise: Implement Topological Sort
Your task is to fill in the blanks in the TopologicalIterator class so that it successively returns vertices in topological order as described above. The TopologicalIterator class will resemble the DFSIterator class, except that it will use a currentInDegree array as described above, and instead of pushing unvisited vertices on the stack, it will push only vertices whose in-degree is 0. Try to walk through this algorithm, where you succesively process vertices with in-degrees of 0, on our DAG example above.
D. Conclusion
Submission
Submit as lab19:
- The completed
Graph.java Survey.javawith the secret word from this week's self-reflection
Reading
For next lab, please read DSA chapter 13.5 (in Graphs).