A. Intro
Obtaining the Files
Pull the files for lab 21 from the skeleton.
Learning Goals
In today's lab, we'll be discussing sorting, or algorithms for rearranging elements in a collection into non-decreasing order. A sorted collection provides several advantages: we can perform binary search in $O(\log N)$ time, efficiently identify adjacent pairs within the list, find the kth largest element, and so forth.
The methods we'll be working with will sort an array or linked list of integers, but the same ideas can be easily adapted to work with any collection of Comparable objects.
There are several kinds of sorting algorithms, each of which is appropriate for different situations. At the highest level, we will distinguish between two types of sorting algorithms:
- Comparison-based sorts which rely on making pairwise comparisons between elements.
- Counting-based sorts which group elements based on their individual digits before sorting and combining each group. Counting sorts do not need to compare individual elements to each other.
In this lab, we will discuss several comparison-based sorts including insertion sort, selection sort, merge sort, and quicksort. Why all the different sorts? Each sort has a different set of advantages and disadvantages: under certain conditions, one sort may be faster than the other, or one sort may take less memory than the other, and so forth. When working with large datasets (or even medium and small datasets), choosing the right sorting algorithm can make a big difference. Along the way, we'll develop an intuition for how each sort works by exploring examples and writing our own implementations of each sort.
Total order and stability
To put elements in order implies that we can enforce an ordering between any two elements. Given any two elements in a list, according to total order, we should be able to decide which of the two elements is larger or smaller than the other.
However, it's also possible that neither element is necessarily larger or smaller than the other. For instance, if we wish to determine the ordering between the array of two strings, ["sorting", "example"], and we want to order by the length of the string, it's not clear which one should come first because both strings are of the same length 7.
In this case, we can defer to the notion of stability: if a sort is stable, then it will preserve the relative orderings between elements in the list. In the above example then, the resultant array will be ["sorting", "example"] in a stable sort rather than ["example", "sorting"] as is possible in an unstable sort. Remember that, according to our total order by the length of the strings, the second list is still considered correctly sorted even though the relative order of equivalent elements is not preserved.
Discussion: Sorting by Hand
Explain how you would sort a hand of 13 playing cards if you are dealt the cards one-by-one. Your hand should end up sorted first by suit, and then by rank within each suit.
Then explain how you would sort a pile of 300 CS 61BL exams by two-letter login. If it's different than your card-sorting algorithm of the previous step, explain why.
Using words, roughly describe an algorithm to formalize your sort. Compare with your partner. Can you tell if one is faster than the other? How so?
Visualizations
Here are several online resources for visualizing sorting algorithms. As you're introduced to new each new sorting algorithm, use these resources as tools to help build intuition about how each sort works.
- VisuAlgo
- Sorting.at
- Sorting Algorithms Animations
- USF Comparison of Sorting Algorithms
- AlgoRhythmics: sorting demos through folk dance including insertion sort, selection sort, merge sort, and quicksort
B. Insertion Sort
The first comparison-based sort we'll learn is called an insertion sort. The basic idea for insertion sort can be formally summed up as follows:
- Start a loop over all items in your collection.
- For each item you find, insert it into its correct place among all the items you've looked at so far.
You might have intuited insertion sort when we asked you how to sort cards. This is like when you sort cards by continually putting the next card in the right spot in a group of sorted cards that you're holding.
Here is code that applies the insertion sort algorithm (to sort from small to large) to an array named arr.
public static void insertionSort (int[] arr) {
for (int i = 1; i < arr.length; i++) {
for (int j = i; j > 0 && arr[j] < arr[j - 1]; j--) {
swap(arr, j, j - 1);
}
}
}Self-test: Best and Worst Case Conditions
Analyze the insertionSort code given above carefully. In particular, consider the comparison step in the for loop condition.
Assume we have an array with a million integers. What would the array have to look like before we ran insertion sort that would make insertion sort run the fastest, i.e. minimizing the number of steps needed?
|
Sorted array
|
Correct! If the array is already sorted, we only need to perform one comparison in the inner loop per iteration of the outer loop. In this case, the current element,
arr[i]
, will be larger than the rest of the already-sorted section so we stop after one comparison.
|
|
|
Reverse-sorted array
|
Incorrect. Think about how many comparisons you need to do to insert the last unsorted element (which is small) into the sorted array, which is arranged from smallest to largest.
|
|
|
Randomly-ordered array
|
Incorrect. Think about how many comparisons you need to do on average.
|
What ordering would maximize the number of comparisons and result in the slowest runtime?
|
Sorted array
|
Incorrect. Refer to the question above to see why this would actually minimize the number of comparisons.
|
|
|
Reversed-sorted array
|
Correct!
|
|
|
Randomly-ordered array
|
Incorrect. Think about how many comparisons you need to do on average.
|
Exercise: Insertion Sort on Linked Lists
We gave you the code for insertion sort on an array. To test if you understand the algorithm, try applying it to a linked list.
The file IntList.java contains an implementation of a doubly-linked list along with methods for sorting the list values. Write the insert method to complete the insertion sort algorithm.
Variation: Tree Sort
We can generalize insertion sort above with the following pseudocode:
for each element in the collection:
insert it into its proper place in another collection.The insertion sort algorithm we just considered performed insertion into an array where elements had to be shifted over one-by-one to make room for the new elements. Choice of a structure that allows faster insertion, namely, a binary search tree, produces a faster algorithm. Recall that insertion into a binary search tree runs in time logarithmic with the number of items in comparison with insertion into an array which is linear.
So, an alternative to insertion sort is to first build the tree through repeated insertions, and then at the end then traverse it in linear time to produce the sorted sequence. This variant of insertion sort is called tree sort.
C. Selection Sort
Selection sort on a collection of N elements can be described by the following pseudocode:
for each element in the collection:
find and remove the smallest remaining element in the unsorted collection
add that element to the end of the sorted collectionGiven below is an implementation of the selection sort algorithm for arrays. You can also see a version for linked lists completed in IntList.java.
for (int k = 0; k < values.length; k++) {
// Elements 0 ... k-1 (sorted collection) are in their proper
// positions in sorted order.
int minSoFar = values[k];
int minIndex = k;
// Find the smallest element among elements k ... N-1.
for (int j = k+1; j < values.length; j++) {
if (values[j] < minSoFar) {
minSoFar = values[j];
minIndex = j;
}
}
// Put the min element in its proper place at the end of the
// sorted collection. Elements 0 ... k are now in their
// proper positions.
swap(values, minIndex, k);
}Self-test: Runtime Analysis
Analyze the code for selection sort carefully. Like insertion sort, is selection sort faster if the array starts off already sorted?
|
Yes
|
Incorrect.
|
|
|
No
|
Correct! Because we need to identify the minimum element, the inner loop must run its entire length no matter what the array looks like. Compare with insertion sort's inner loop, which can stop early if the item just found is already in the correct place.
|
Determine the asymptotic runtime of selection sort. How does it compare with insertion sort? Remember to draw a graph to better visualize how much work needs to be done to move one element from the unsorted collection to the sorted collection.
One may observe that, in the first iteration of the loop, element 0 is compared with all the N-1 other elements. On the next iteration, element 1 is compared with N-2 other elements. On the next, element 2 is compared with N-3 other elements, and so on. The total number of comparisons is $N-1 + N-2 + ... + 1 = \frac{N \times (N-1)}{2}$ no matter what the ordering of elements in the array or linked list prior to sorting.
Hence, we have an $O(N^2)$ algorithm, equivalent to insertion sort's normal case. But notice that selection sort doesn't have a better case, like insertion sort does.
Can you come up with any reason we would want to use selection sort over insertion sort?
Variation: Heap Sort
Recall the basic structure for selection sort
for each element in the collection:
find and remove the smallest remaining element in the unsorted collection
add that element to the end of the sorted collectionAdding something to the end of a sorted array or linked list can be done in constant time. What hurt our runtime was finding the smallest element in the collection, which always took linear time in an array.
Is there a data structure we can use that allows us to find and remove the smallest element quickly? A min heap fits the bill; removal of the largest element from a heap of $N$ elements can be done in time proportional to $\log N$. Recall that we can also build a heap in linear time using the bottom-up heapify algorithm. This step is only done once, so it doesn't make our overall runtime worse than $O(N \log N)$ that we previously established. So, once the heap is created, sorting can be done in $O(N \log N)$.
Can you prove to yourself why this runtime is the case? It's not exactly as simple as $N \times \log N$ because later removals only need to sift through a smaller and smaller heap. (The complete technical analysis for heap sort's runtime falls a little bit outside of the scope of this course but it's worthwhile to draw a visual to approximate the runtime for this sort. See Stirling's approximation if you'd like to see more of the math.)
If you haven't already, take a little bit of time right now to study the visualizations for insertion sort and selection sort. Try to predict which element will move next as well as its movement pattern.
D. Merge Sort
The first two sorting algorithms we've introduced work by iterating through each item in the collection one-by-one. With insertion sort and selection sort, both maintain a "sorted section" and an "unsorted section" and gradually sort the entire collection by moving elements over from the unsorted section into the sorted section. With merge sort and quicksort, however, we'll introduce a different class of comparison-based sorting algorithms based around the idea of divide and conquer.
"Divide and Conquer"
Another approach to sorting is by way of divide and conquer. Divide and conquer takes advantage of the fact that empty collections or one-element collections are already sorted. This essentially forms the base case for a recursive procedure that breaks the collection down to smaller pieces before merging adjacent pieces together to form the completely sorted collection.
The idea behind divide and conquer can be broken down into the following 3-step procedure.
- Split the elements to be sorted into two collections.
- Sort each collection recursively.
- Combine the sorted collections.
Compared to selection sort, which involves comparing every element with every other element, divide and conquer can reduce the number of unnecessary comparisons between elements by sorting or enforcing order on sub-ranges of the full collection. The runtime advantage of divide and conquer comes largely from the fact that merging already-sorted sequences is very fast.
Two algorithms that apply this approach are merge sort and quicksort.
Merge Sort
Merge sort works by executing the following procedure until the base case of an empty or one-element collection is reached.
- Split the collection to be sorted in half.
- Recursively call merge sort on each half.
- Merge the sorted half-lists.
The reason merge sort is fast is because merging two lists that are already sorted takes linear time proportional to the sum of the lengths of the two lists. In addition, splitting the collection in half requires a single pass through the elements. The processing pattern is depicted in the diagram below.
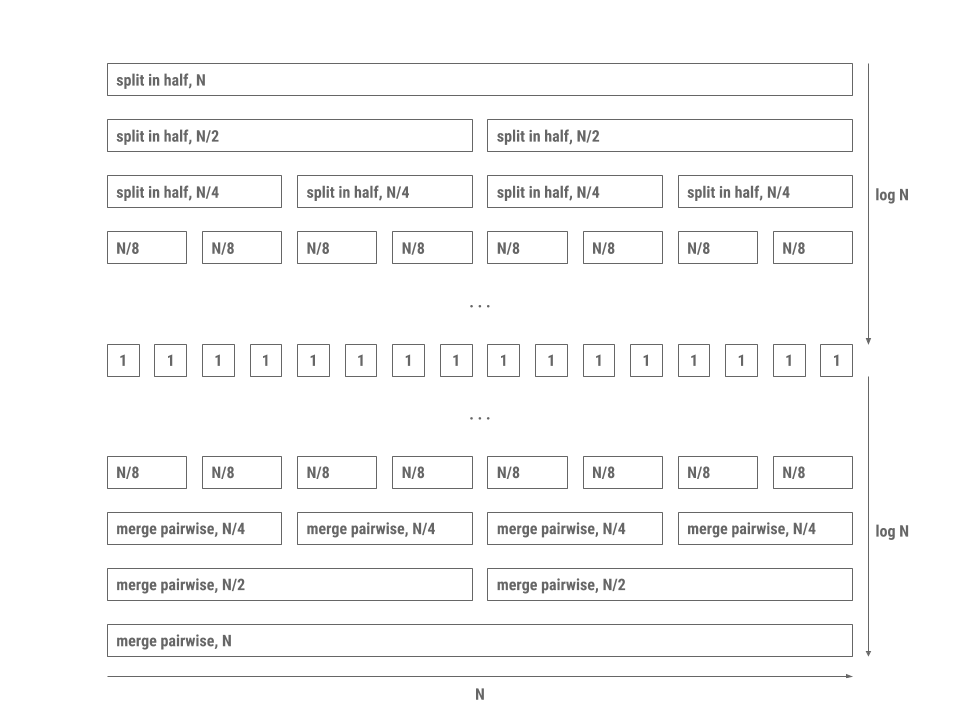
Each level in the diagram is a collection of processes that all together run in linear time. Since there are $2 \log N$ levels with each level doing work proportional to $N$, the total time is proportional to $N \log N$.
Exercise: Merge Sort on Linked Lists
To test your understanding of merge sort, fill out the mergeSort method in IntList.java. Be sure to take advantage of the provided merge method!
E. Quicksort
Another example of dividing and conquering is the quicksort algorithm:
- Split the collection to be sorted into two or more collections by partitioning around a pivot (or "divider"). One collection consists of elements smaller than the pivot while the other consists of elements greater than or equal to the pivot.
- Recursively call quicksort on the each collection.
- Merge the sorted collections by concatenation.
Here's an example of how this might work, sorting an array containing 3, 1, 4, 5, 9, 2, 8, 6.
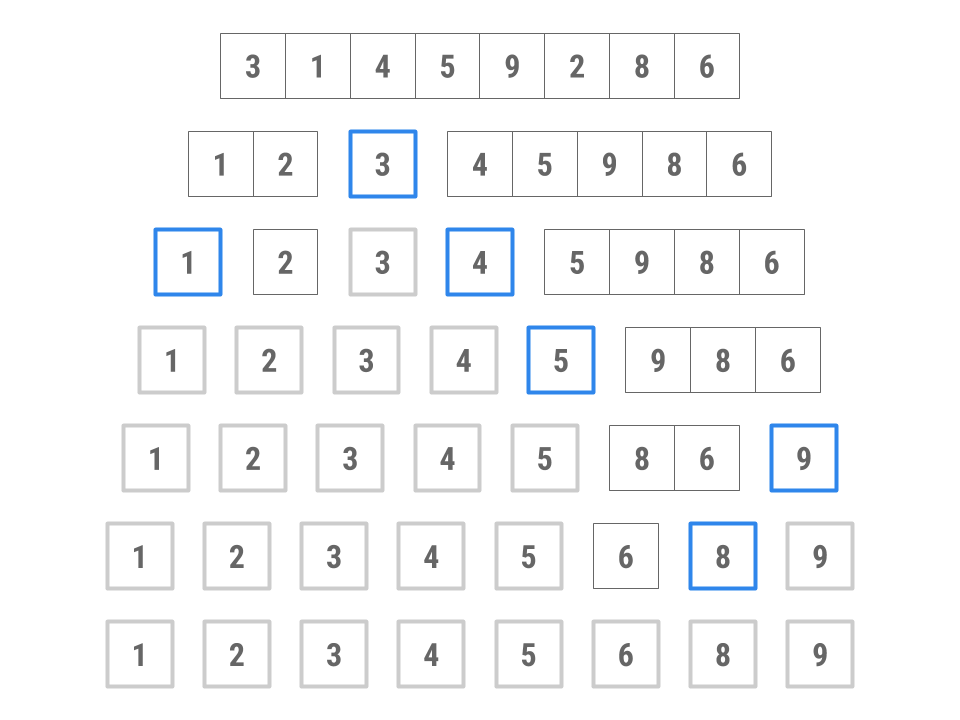
- Choose 3 as the pivot. (We'll explore how to choose the pivot shortly.)
- Put 4, 5, 9, 8, and 6 into the "large" collection and 1 and 2 into the "small" collection.
- Sort the large collection into 4, 5, 6, 8, 9; sort the small collection into 1, 2; combine the two collections with the pivot to get 1, 2, 3, 4, 5, 6, 8, 9.
Exercise: Quicksort on Linked Lists
Some of the code is missing from the quicksort method in IntList.java. Fill in the function to complete the quicksort implementation.
Be sure to use the supplied helper methods! They will make your job a lot easier.
Self-test: Runtime analysis
First, let's consider the best-case scenario where each partition divides a range optimally in half. Using some of the strategies picked up from the merge sort analysis, determine a big-Oh figure for quicksort's asymptotic runtime behavior and explain some of the differences between the two algorithms' runtimes. Can you identify which one is faster? (It's okay to be a little informal here.)
Quicksort's best case is $O(N \log N)$, just like merge sort.
However, quicksort is faster in practice and tends to have better constant factors (which aren't included in the big-Oh analysis). To see this, let's examine exactly how quicksort works.
We know concatenation in a linked list can be done in constant time or linear time if it's an array. Partitioning can be done in time proportional to the number of elements $N$. If the partitioning is optimal and splits each range more or less in half, we have a similar logarithmic division of levels downward like in merge sort. On each division, we still do the same linear amount of work as we need to decide whether each element is greater or less than the pivot.
However, once we've reached the base case, we don't need as many steps to reassemble the sorted collection. Remember that with merge sort, while each list of one element is sorted with respect to itself, the entire set of one-element lists is not necessarily in order which is why there are $\log N$ steps to merge upwards in merge sort. This isn't the case with quicksort as each element is in order. Thus, merging in quicksort is simply one level of linear-time concatenation.
Unlike merge sort, quicksort has a worst-case runtime different from its best-case runtime. Suppose we always choose our the first element in a range as our pivot. Then, which of the following conditions would cause the worst-case runtime for quicksort?
|
Sorted array
|
Correct! On each step of quicksort, all the elements will go to one side of the pivot, thus only reducing the number of elements to sort by 1. This means quicksort will have to make about $N$ recursive calls before it hits its base case, rather than $\log N$.
|
|
|
Reverse sorted array
|
Correct! Do you see how the same reasoning applies as for the sorted array?
|
|
|
Mostly unsorted array
|
Incorrect. In this case, on average, we can expect to split the array roughly in half at each step. This means quicksort will only have to make about $\log N$ recursive calls before it hits its base case.
|
Under these conditions, does this special case of quicksort remind you of any other sorting algorithm we've discussed in this lab?
Discussion: Choosing a Pivot
Given a random collection of integers, what's the best possible choice of pivot for quicksort that will break the problem down into $\log N$ levels? Describe an algorithm to find this pivot element. What is its runtime? It's okay if you think your solution isn't the most efficient.
Practical Methods for Selecting the Pivot
How fast was the pivot-finding algorithm that you came up with? Finding the exact median of our elements may take so much time that it may not help the overall runtime of quicksort at all. It may be worth it to choose an approximate median, if we can do so really quickly. Options include picking a random element, or picking the median of the first, middle, and last elements. These will at least avoid the worst case discussed in the self-test.
Quicksort Performance in Practice
For reasons that can't be explained with asymptotic runtime analysis, in practice, quicksort turns out to be the fastest of the general-purpose sorting algorithms we have covered so far. It tends to have better constant factors than that of merge sort, for example. For this reason, it's the algorithm used in Java for sorting arrays of primitive types like int or float. With some tuning, the most likely worst-case scenarios are avoided, and the average case performance is excellent.
Here are some improvements to the quicksort algorithm as implemented in the Java standard library.
- When there are only a few items in a sub-collection (near the base case of the recursion), insertion sort is used instead.
- For larger arrays, more effort is expended on finding a good pivot.
- Various machine-dependent methods are used to optimize the partitioning algorithm and the
swapoperation. - Dual pivots
For object types, however, Java uses a hybrid merge sort/insertion sort called "Timsort" instead of quicksort. Can you come up with an explanation as to why?
F. Conclusion
Summary
In this lab, we learned about different comparison-based algorithms for sorting collections. Within comparison-based algorithms, we examined two different paradigms for sorting:
- Simple sorts like insertion sort and selection sort which demonstrated algorithms that maintained a sorted section and moved unsorted elements into this sorted section one-by-one. With optimization like heap sort or the right conditions (relatively sorted list in the case of insertion sort), these simple sorts can be fast!
- Divide and conquer sorts like merge sort and quicksort. These algorithms take a different approach to sorting: we instead take advantage of the fact that collections of one element are sorted with respect to themselves. Using recursive procedures, we can break larger sorting problems into smaller subsequences that can be sorted individually and quickly recombined to produce a sorting of the original collection.
Submission
Turn in the completed IntList.java.