
Introduction
As we discussed in the previous lab, there are a few ADT’s that are critical building blocks to more complex structures. Today, we will explore an implementation of the Set ADT called disjoint sets and apply what we learn to a real-life example of percolation.
As usual, pull the files from the skeleton and make a new IntelliJ project.
Disjoint Sets
Suppose we have a collection of companies that have gone under mergers or acquisitions. We want to develop a data structure that allows us to determine if any two companies are in the same conglomerate. For example, if company X and company Y were originally independent but Y acquired X, we want to be able to represent this new connection in our data structure. How would we do this? One way we can do this is by using the disjoint sets data structure.
The disjoint sets data structure represents a collection of sets that are disjoint, meaning that any item in this data structure is found in no more than one set. When discussing this data structure, we often limit ourselves to two operations, union and find, which is also why this data structure is sometimes called the union-find data structure. We will be using the two interchangeably for the remainder of this lab.
The union operation will combine two sets into one set. The find operation will take in an item, and tell us which set that item belongs to. With this data structure, we will be able to keep track of the acquisitions and mergers that occur!
Let’s run through an example of how we can represent our problem using disjoint sets with the following companies:
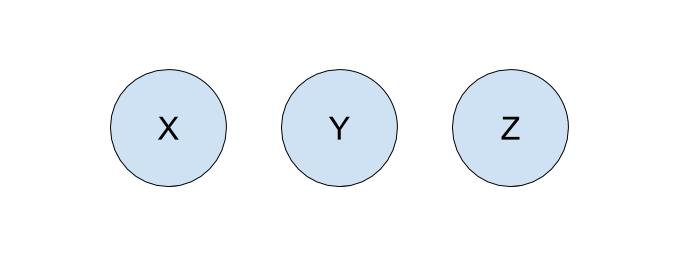
To start off, each company is in its own set with only itself and a call to find(X) will return (and similarly for all the other companies). If acquired , we will make a call to union(X, Y) to represent that the two companies should now be linked. As a result, a call to find(X) will now return , showing that is now a part of . The unioned result is shown below.
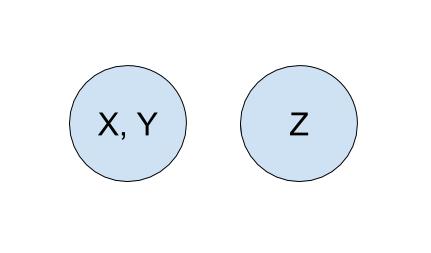
Quick Find
For the rest of the lab, we will work with non-negative integers as the items in our disjoint sets.
In order to implement disjoint sets, we need to know the following:
- What items are in each set
- Which set each item belongs to
One implementation we can do involves keeping an array that details just that. In our array, the index will represent the item (hence non-negative integers) and the value at that index will represent which set that item belongs to. For example, if our set looked like this,
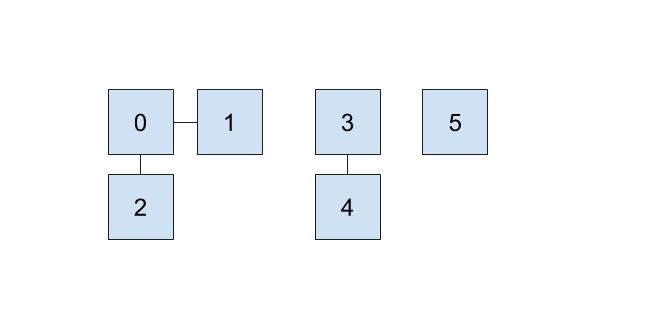
then we could represent the connections like this:
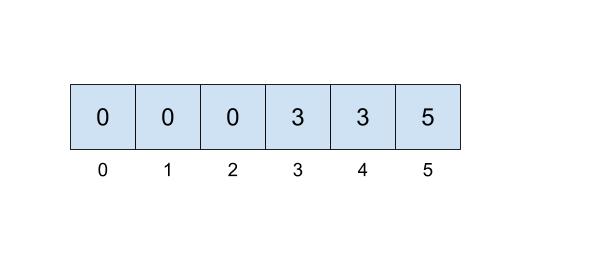
Here, we will be choosing the smallest number of the set to represent the face of the set, which is why the set numbers are 0, 3, and 5.
This approach uses the quick-find algorithm, prioritizing the runtime of the find operation but making the union operations slow. But, how fast is the find operation in the worst case, and how slow is the union operation in the worst case? Discuss with your partner, then answer the corresponding questions in the Gradescope assessment. Hint: Think about the example above, and try out some find and union operations yourself!
Quick Union
Suppose we prioritize making the union operation fast instead. One way we can do that is that instead of representing each set as we did above, we will think about each set as a tree. We will cover trees more in-depth in the next lab, but know that trees are made up of nodes and connections between nodes, as well as the notion of parent-child relationships between these nodes.
This tree will have the following qualities:
- the nodes will be the items in our set,
- each node only needs a reference to its parent rather than a direct reference to the face of the set, and
- the top of each tree (we refer to this top as the “root” of the tree) will be the face of the set it represents.
In the example from the beginning of lab, would be the face of the set represented by and , so would be the root of the tree containing and .
How do we modify our data structure from above to make this quick union? We will just need to replace the set references with parent references! The indices of the array will still correspond to the item itself, but we will put the parent references inside the array instead of direct set references. If an item does not have a parent, that means this item is the face of the set and we will instead record the size of the set. In order to distinguish the size from parent references, we will record the size, , of the set as inside of our array.
When we union(u, v), we will find the set that each of the values belong to (the roots of their respective trees), and make one the child of the other. If u and v are both the face of their respective sets and in turn the roots of their own tree, union(u, v) is a fast operation because we just need to make the root of one set connect to the root of the other set!
The cost of a quick union, however, is that find can now be slow. In order to find which set an item is in, we must jump through all the parent references and travel to the root of the tree, which is in the worst case. Here’s an example of a tree that would lead to the worst case runtime, which we often refer to as “spindly”:
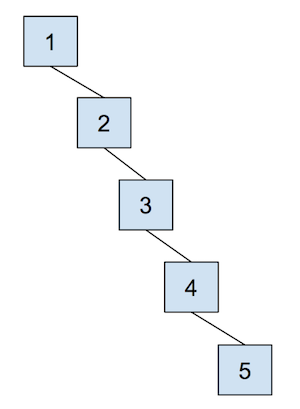
In addition, union-ing two leaves could lead to the same worst case runtime as find because we would have to first find the sets that each of the leaves belong to before completing union operation. We will soon see some optimizations that we can do in order to make this runtime faster, but let’s go through an example of this quick union data structure first. The array representation of the data structure is shown first, followed by the abstract tree representation of the data structure.
Initially, each item is in its own set, so we will initialize all of the elements in the array to -1.
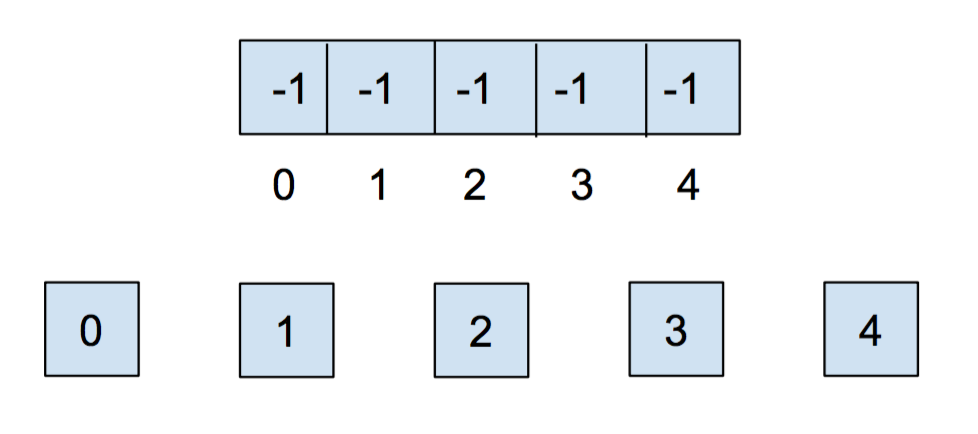
After we call union(0,1) and union(2,3), our array and our abstract representation look as below:
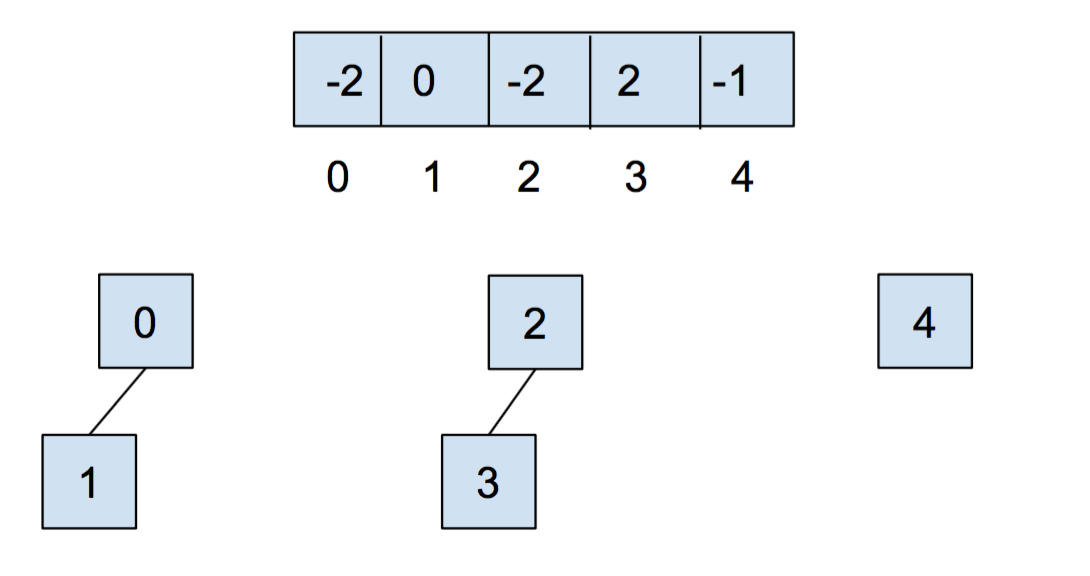
After calling union(0,2), they look like:
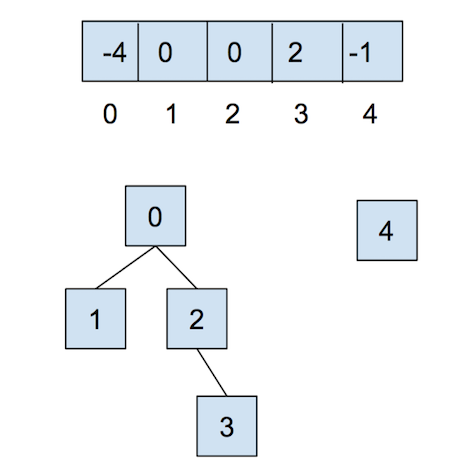
Now, let’s combat the shortcomings of this data structure with the following optimizations.
Weighted Quick Union
The first optimization that we will do for our quick union data structure is called “union by size”. This will be done in order to keep the trees as shallow as possible and avoid the spindly trees that result in the worst-case runtimes. When we union two trees, we will make the smaller tree (the tree with less nodes) a subtree of the larger one, breaking ties arbitrarily. We call this weighted quick union.
Because we are now using “union by size”, the maximum depth of any item will be in , where is the number of items stored in the data structure. This is a great improvement over the linear time runtime of the unoptimized quick union. Some brief intuition for this depth is because the depth of any element only increases when the tree that contains is placed below another tree . When that happens, the size of the resulting tree will be at least double the size of because . The tree that contains only can double its size at most times until we have reached a total of items.
Complete the Gradescope assessment which asks you to consider how a weighted quick union will grow in the best and worst case.
Path Compression
Even though we have made a speedup by using a weighted quick union data structure, there is still yet another optimization that we can do. What would happen if we had a tall tree and called find repeatedly on the deepest leaf? Each time, we would have to traverse the tree from the leaf to the root.
A clever optimization is to move the leaf up the tree so it becomes a direct child of the root. That way, the next time you call find on that leaf, it will run much more quickly. An even more clever idea is that we could do the same thing to every node that is on the path from the leaf to the root, connecting each node to the root as we traverse up the tree. This optimization is called path compression. Once you find an item, path compression will make finding it (and all the nodes on the path to the root) in the future faster.
The runtime for any combination of find and union operations takes time, where is an extremely slowly-growing function called the inverse Ackermann function. And by “extremely slowly-growing”, we mean it grows so slowly that for any practical input that you will ever use, the inverse Ackermann function will never be larger than 4. That means for any practical purpose, a weighted quick union data structure with path compression has find operations that take constant time on average!
You can visit this link here to play around with disjoint sets.
Exercise: UnionFind
We will now implement our own disjoint sets data structure. When you open up UnionFind.java, you will see that it has a number of method headers with empty implementations.
Read the documentation to get an understanding of what methods need to be filled out. Remember to implement both optimizations discussed above, and take note of the tie-breaking scheme that is described in the comments of some of the methods. This scheme is done for autograding purposes and is chosen arbitrarily. In addition, remember to ensure that the inputs to your functions are within bounds, and should otherwise throw an IllegalArgumentException.
Discussion: UnionFind
Our UnionFind uses only non-negative values as the items in our set.
How can we use the data structure that we created above to keep track of different values, such as all integers or companies undergoing mergers and acquisitions? Discuss with your partner.
Percolation
Next, we’ll work on an application of the disjoint sets data structure and create a model of a percolating system.
Percolation is the process of a liquid passing through a porous substance. For example, if we’re given a porous landscape, liquids such as water will be able to percolate through the landscape.
We will model a percolating system using an -by- grid of sites. Each site is either open or blocked. A full site is an open site that can be connected to an open site in the top row via a chain of neighboring (left, right, up, down) open sites. We say the system percolates if there is a full site in the bottom row. In other words, a system percolates if we fill all open sites connected to the top row and that process fills some open site on the bottom row. (For the porous substance example, the open sites correspond to empty space through which water might flow, so a system that percolates lets water fill the open sites, flowing from top to bottom.)
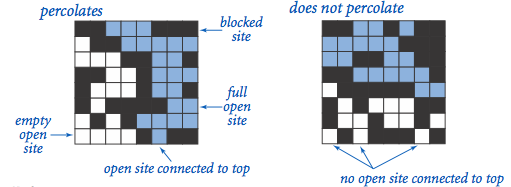
Exercise: Percolation
To model a percolation system, you will have to implement the following methods in the provided Percolation class:
public class Percolation {
public Percolation(int N) // create N-by-N grid with all sites initially blocked
public void open(int row, int col) // open the site (row, col) if it is not open already
public boolean isOpen(int row, int col) // is the site (row, col) open?
public boolean isFull(int row, int col) // is the site (row, col) full?
public int numberOfOpenSites() // number of open sites
public boolean percolates() // does the system percolate?
public static void main(String[] args) // use for unit testing (not required)
}
In order for your code to be gradable by our autograder, your code must use the WeightedQuickUnionUF class that’s been imported for you at the top of the file, not the UnionFind data structure you implemented earlier.
By convention, the row and column indices are integers between and , where is the upper-left site.
If any argument to open, isOpen, or isFull is outside its prescribed range, throw an IndexOutOfBoundsException.
The constructor should throw an IllegalArgumentException if . The constructor should take time proportional to ; all methods should take constant time plus a constant number of calls to the WeightedQuickUnionUF functions:
unionfindconnectedcount
Your numberOfOpenSites method must take constant time as well.
For a visual example about how this system works and some hints to implement this system, please see these slides.
You can visually test your code with the provided
PercolationVisualizerfile by passing in one of the files in theinputFilesdirectory as an argument, and compare the output with the corresponding image from theoutputFilesdirectory.In IntelliJ, make sure the top right corner arrow drop-down tab says
PercolationVisualizer. Click the drop-down, and then click Edit Configurations…. Then, in the Program arguments line, putinputFiles/FILE_NAMEand click OK. Then, run the file by hitting the green arrow in the top right corner.Additionally, you can use the
InteractivePercolationVisualizerto play around with opening different sites and visually test your percolating system.
After implementing Percolation, let’s time your data type in PercolationTimer. Run the main method and see how long it takes to run through the given input file. Then, run the main methods again when replacing your WeightedQuickUnionUF data structures with QuickUnionUF, and then QuickFindUF (The methods are the same, so the only change you will need to do is in the instantiation of any WeightedQuickUnionUF objects).
Do the times that you recorded match what you expect? Why are the times that you recorded the way they are? Discuss this with your partner.
Make sure to revert your Percolation class back to WeightedQuickUnionUF and remove the import statements that you don’t use when you submit to the autograder!
Recap
- Algorthm Development
- Developing a good algorithm is an iterative process. We create a model of the problem, develop an algorithm, and revise the performance of the algorithm until it meets our needs.
- Dynamic Connectivity Problem
- The ultimate goal of this lab was to develop a data type that support the following operations on objects:
connect(int p, int q)(calledunionin our optional textbook)isConnected(int p, int q)(calledconnectedin our optional textbook)
We do not care about finding the actual path between p and q. We care only about their connectedness. A third operation we can support is very closely related to connected:
find(int p): Thefindmethod is defined so thatfind(p) == find(q)if and only ifconnected(p, q). We did not use this in class.
- Connectedness is an equivalence relation
- Saying that two objects are connected is the same as saying they are in an equivalence class. This is just fancy math talk for saying “every object is in exactly one bucket, and we want to know if two objects are in the same bucket”. When you connect two objects, you’re basically just pouring everything from one bucket into another.
- Quick find
- This is the most natural solution, where each object is given an explicit number. Uses an array
idof length , whereid[i]is the bucket number of objecti(which is returned byfind(i)). To connect two objectspandq, we set every object inp’s bucket to haveq’s number.
connect: May require many changes toid. Takes time, as the algorithm must iterate over the entire array.isConnected(andfind): take constant time.
Performing operations takes time in the worst case. If is proportional to , this results in a runtime.
- Quick union
- An alternate approach is to change the meaning of our
idarray. In this strategy,id[i]is the parent object of objecti. An object can be its own parent. Thefindmethod climbs the ladder of parents until it reaches the root (an object whose parent is itself). To connectpandq, we set the root ofpto point to the root ofq.
connect: Requires only one change toid, but also requires root finding (worst case time).isConnected(andfind): Requires root finding (worst case time).
Performing operations takes time in the worst case. Again, this results in quadratic behavior if is proprtional to .
- Weighted quick union
- Rather than
connect(p, q)making the root ofppoint to the root ofq, we instead make the root of the smaller tree point to the root of the larger one. The tree’s size is the number of nodes, not the height of the tree. Results in tree heights of .
connect: Requires only one change toid, but also requires root finding (worst case time).isConnected(andfind): Requires root finding (worst case time).
Warning: if the two trees have the same size, the book code has the opposite convention as quick union and sets the root of the second tree to point to the root of the first tree. This isn’t terribly important (you won’t be tested on trivial details like these).
- Weighted quick union with path compression
- When
findis called, every node along the way is made to point at the root. Results in nearly flat trees. Making calls to union and find with objects results in no more than array accesses, not counting the creation of the arrays. For any reasonable values of in this universe that we inhabit, is at most 5.
Deliverables
To receive credit for this lab:
- Complete the implementation of
UnionFind.java - Complete the implementation of
Percolation.java - Answer the questions in the Gradescope assessment.