
Before You Begin
It will be helpful to have a passing familiarity with the Project 2: Gitlet specification, just so you have a sense of the scope of the project and a rough idea of the general requirements of the system. If you haven’t had chance to read it yet, that’s okay as part of this lab’s exercises will be an application of techniques towards designing your Gitlet implementation.
The activities in this lab will require working together with your Gitlet super-group. All members need to be present for this lab.
Learning Goals
In this lab, we’ll be exploring deeper into the art and practice of software engineering, which combines all of the ideas we’ve learned in the course to this point.
For the most part, our discussion of design trade-offs in the course have mainly focused around relatively small snippets of code. We learned algorithmic analysis to make arguments about the execution costs of a piece of code, and this week we’ve looked more closely at some of the programming costs incurred from the writing, improvement, and maintenance of a programming product.
The question for this lab is, “What are the considerations we need to make when working in teams to build large programs that need to be modified or improved over the course of its lifespan?”
Programming Products
Designing a programming product is different from ‘simple programming’.
- Programming products combine the work of many programmers
- It’s not always the case that programmers share a common understanding of every component of the program. Code that is written by one programmer may not be easily understood by another programmer, or even the original programmer themselves weeks or months down the line. Working in teams imposes real stress that is not evident from working alone.
- Programming products are prepared for use by other people
- Unlike software that is written by programmers, for programmers, or purely ‘academic’ problems which aren’t used in a real setting, programming products need to meet the requirements of the client or target user. Unfortunately, clients and users rarely, if ever, completely understand what their programming product should do; instead, they often have a vague notion of a problem. Part of the challenge of software engineering is in acquiring a deep-enough mental model of the fundamental problem the client is facing in order to choose between multiple possible solutions.
In short, software engineering is concerned with the problem of “multi-person development of multi-version programs”.
Human-Centered Design
Programming products are designed, in one way or another, to be used by or otherwise affect a human. Software systems communicate with people.
CSCW [is] a generic term, which combines the understanding of the way people work in groups with the enabling technologies of computer networking, and associated hardware, software, services and techniques.
For example, consider the area of computer-supported cooperative work (CSCW). Principles that govern group behavior are often subtle and non-obvious. Social and organizational dynamics are at play, so it’s easy to get it wrong.
Consider shared calendars on Google Calendar as a concrete example of a groupware application. Groupware applications often require additional work from individuals who do not perceive a direct benefit from the use of the application.
Early shared calendars at Sun were a failure because there was a disparity between the employees who were obligated to put in the work to log their hours and how they spent their time at work, versus the managers who gained the benefit of ease of scheduling meetings.
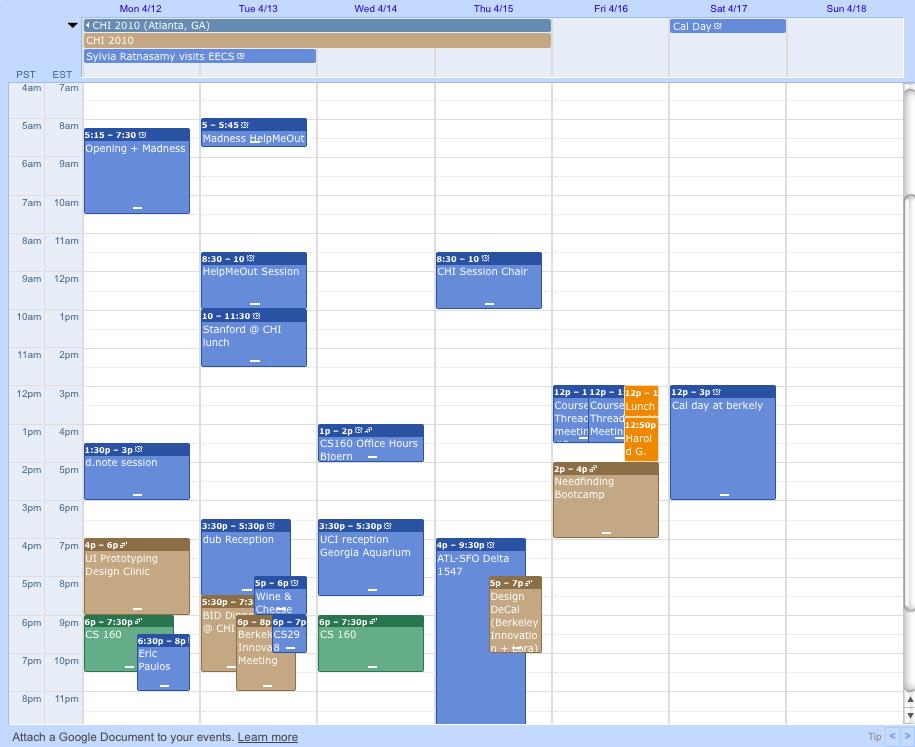
In Google Calendar, however, there is an option to only share free/busy without sharing all the full event details.

By including something as simple as an option to toggle between sharing all event details, and sharing only the free/busy information, the social dynamic between employees and managers changed. Employees could block out time in their workdays and regain a bit of privacy and control over their workdays while managers could still readily schedule meetings based on everyone’s desired availability.
The technical hurdle for implementing this isn’t that complex, but the idea and the design of the product was what made it more successful than competing products.
Now, not all programming products will impact users as directly as CSCW, but it can’t be understated how important it is to emphasize that it is the product, and not the programming, that is ultimately delivered.
When it comes to designing the right product, part of the task will be solved by user experience designers, product managers, and other business experts whose job is to perform controlled studies and experiments to determine which designs best meet the demands of the market. However, within this hierarchy, software developers still make many code-level decisions on their own based on their model of the client.
For more on this, take a course in user interfaces or user experience design.
Communication
In multiperson programming we find three problems that are not significant in the solo-programming situation:
- How to divide the job of producing the software among the programmers
- How to specify the exact behavior required of each program component
- How to communicate to all the people involved information about the occurrence of run-time errors among the system components and to the user.
—David Parnas
Read about Communication from Andrew Ko.
One of the greatest challenges in designing a large system like Gitlet is organizing the team and structuring the project so as to maximize team productivity. In prior lab exercises and assignments, the work of implementing the project was done in pairs working in close communication, with each partner learning each part of the system together. With larger teams, however, simply adding more people and expecting the productivity to increase doesn’t tend to work well in the real world.
In order to take advantage of each programmer’s individual productivity, we delegate work to individual team members or pairs of team members. By delegating work, each team member can work on a separate part of the program (often called a module) which can then be put together to form the final product.
The difficulty with delegation is making sure that all team members have a shared understanding of how other parts of the program will behave. If team members don’t fully understand the interfaces and classes written by other team members, when it comes time to run the final product, much time will need to be spent rewriting code that was written under a different set of interface assumptions.
Later in the lab, we’ll explore a well-known design principle called information hiding which will help us devise a solution to this problem.
Exercise: Teams
In your super-group, decide how you will communicate.
Setup Communication
For this project, it is okay to use any of your preferred group messaging services or texting for most communications between your team.
When working on projects on teams that are even larger-scale, we’ll often use specialized team communication platforms like Slack to reduce cross-talk between different discussion topics.
Whatever you choose, make sure all members of your team have easy access to this communication tool.
Scheduling Working Meetings
Discussion and verbal communication are often much more efficient at conveying complex ideas than text, but often comes at the cost of needing to coordinate everyone’s schedules.
Therefore, you should also schedule team meetings in advance. Meetings are fantastic forcing functions to help you get work done because they serve as social deadlines. Peer pressure is a powerful motivator. Your team should use that to its advantage.
For this project, meetings will probably run best as working meetings. Unlike ‘regular’ meetings where there is a more strictly-determined agenda, a working meeting can be thought of as a time that everyone agrees to work on the project in the same space. This makes it a lot easier to ask quick questions like, “What did you mean for this function to do?”, or to have another team member provide a second look at your code, or to facilitate pair programming.
On the class schedule, you’ll see that there are multiple labs dedicated to working on projects. These are excellent times to hold team meetings since you will all be in the same place at the same time, but you should also schedule other times outside of class. Coordinate among yourselves to schedule at least 3 working meetings outside of class spread out over the next two weeks. To maximize productivity, expect each meeting to last at least 2 or 3 hours. Team members will likely need to put in additional time outside of these working meetings on the project as well.
Share the schedule for every team meeting, including both time and place, so everyone knows when and where to meet. We prefer sharing bCal events to help organize both in-person and remote meetings.
In addition, don’t hesitate to schedule more working meetings if you realize next week that something needs critical fixing. These meetings should be fairly productive for everyone as the work needs to be done eventually anyways.
To facilitate synchronous remote meetings, your team can create a shared Google Hangout. However, we find that working together in-person is still the best way to talk about particular bits of code and reduces the barrier to interaction.
Honesty
Because coordination is so important to productivity, great software engineers proactively provide credible information regardless of how it influences them personally. If you’re stuck on something, tell someone and get help. If you broke something, tell someone. Don’t let shame and consequence get in the way of shipping.
Now, whether it’s easy to be honest isn’t just an attribute of individual personality and ethics. It’s also an attribute of your social setting. Some organizational cultures incentivize honesty by not punishing it; others might incentivize dishonesty and concealment by firing or reprimanding people who make mistakes. The right thing for your team and your product might be to say something, but it could be the wrong thing for your career.
Because we often can’t change organizational culture factors, today we’ll practice the individual factors. To get good at being honest, in your super-group, share a professional or educational setting in which we weren’t honest and describe the consequences it had. If you’ve never told anyone this, it could be hard, because it might mean experiencing some shame. That’s OK! This class is a place of psychological safety.
Discussion: Information Hiding
Software doesn’t exist in a vacuum. In the real world, software constantly undergoes changes in requirements in response to shifts in requirements.
There are two, quite distinct, types of software aging. The first is caused by the failure of the product’s owners to modify it to meet changing needs; the second is the result of the changes that are made. This “one-two punch” can lead to rapid decline in the value of a software product.
Read Revealing the Secrets of David Parnas.
-
Work with your group to come up with a shared definition for information hiding as it is used in the excerpt below. Then, come up with a couple examples of instances where we’ve used the principle of information hiding in this course.
Parnas uses information hiding to decompose the system in modules that satisfy his goals; each module keeps its own secreta design decision about some aspect of the system (e.g., choice of a data structure). A module’s design decision can change but none of the other modules should be affected.
-
Consider the following claim from the paper.
[Parnas] defines the “interface between programs” to consist “of the set of assumptions that each programmer needs to make about the other program in order to demonstrate the correctness of his own program.” In addition to an operation signature, these assumptions must specify the restrictions on data passed to the operation, the effect of the operation, and exceptions to the normal processing that may arise.
How can information hiding affect the number of assumptions a programmer needs to make? How is testing related to the assumptions that come with designing a particular program method?
-
One aspect of information hiding is encapsulation, an idea we’ve already explored several times in the course. Can you think of other examples outside of encapsulation where the hiding information from the programmer has been helpful or desirable?
A secret of a well-designed module is more than hidden data. It is any aspect that can change as the system evolves: processing algorithms used, hardware devices accessed, other modules present, and specific functional requirements supported.
In what ways has technology changed in the past 5 or 10 years? What kind of gadgets and software services have become popular in recent years? How can information hiding help software adapt to these changes?
Designing for Change
In multi-version programming we find three additional problems that are not present if we are going to write a single program:
- How to write programs that are easily modified. Programs in which a change of one design decision does not require changes in many parts of the program.
- How to write programs with useful subsets. If we only need a subset of the services performed by a program we shold be able to quickly remove unneeded parts without having to rewrite the remainder. If we are unable to complete or use certain functions, we would like a reduced set of capabilities to be available.
- How to write programs that are easily extended. We should like to be able to add new capabilities to programs without rewriting the programs that are already present. This, too, is a fail soft goal; build a subset to meet a deadline, then extend as time permits.
—David Parnas
Read about the principles of Software Architecture from Andrew Ko. A summary of some of the key ideas appears below.
Apply:
- Information hiding
- Abstraction
- Separation of concerns
- Data hiding
- Object orientation
Begin by characterizing likely classes of changes.
- Do not begin with data structures
- Do not begin with algorithms
- Think about change as part of documenting requirements
- Changeability is a requirement and should be treated as such.
Estimate the probabilities of each type of change.
- We cannot make everything equally easy to change.
- Our intuition on what will change is often wrong, but we can consult clients as well as more experienced software engineers for feedback.
- Oftentimes, we won’t know what will be more likely to change, but an educated guess is better than nothing.
- Review changeability at every step in the design.
Then, organize the software to confine or encapsulate likely changes.
- Provide an abstract interface that is unlikely to change.
- Implement objects that hide changeable data structures.
Experience has shown that, even if unanticipated changes are eventually required, software designed for ease of change is easier to maintain than software designed without concern for future changes.
DRY
When working on any software project, the principle of “Don’t repeat yourself”, or DRY, is one of the simplest but also most general principles for writing maintainable software. We’ve already seen several examples of this in action when we designed the Comparable, Comparator and Iterable, Iterator interfaces.
Each of these methods reduced our need to make near-copies of code throughout our program. In the textbook, we saw that, before the idea of Comparable, we would need to implement a different max function for each type of Animal: we’d need to write a maxDog function, “a maxCat function, a maxPenguin function, a maxWhale function, etc., resulting in unnecessary repeated work and a lot of redundant code.”
In Java, our solution to improve code reuse is to extract repeated code snippets into methods or other subroutines. For each variable or value that differs between the code snippets, parameterize the variables, turning them into parameters that can be passed into the function by the caller.
DRY, as a design philosophy, is interesting because it takes the approach of write code first, then abstract it away second. Unlike upfront design where all the decisions are made at the start, pulling code out into a method can be done at the precise time when the abstraction is needed. But DRY is not incompatible with information hiding. The better way to formulate the problem may be to say that, if information hiding is responsible for managing the complexity of the high-level program architecture, DRY can be thought of as a technique to help programmers manage complexity as they implement each individual class.
Exercise: Gitlet Architecture
One key idea in designing architecture is to imagine you’re inventing new “species” of creatures. Unlike living species, however, which are concerned with survival, your components are entities that have responsibilities for storing data and accomplishing computation of some kind. Inventing new species is a creative activity; you want to think about what they will and won’t do, give them names, and tell stories about how they interact with each other, exchanging data.
—Andrew Ko
Work on the Gitlet Design Process. This will be due in lab on Monday so it’s okay if you haven’t fully determined all the details.
Take this time to first ensure that all team members have an idea of the scope of the project. What is the problem that Gitlet aims to solve? How does Gitlet propose to solve that problem? What kind of mental models and representations are used as part of Gitlet?
Design Document
Compose a design document that specifies all the classes in your design. For each class:
- Include a name.
- Give a natural language descriptions of the class’s responsibilities.
- Enumerate the data and functionality it will encapsulate.
- For each kind of data, specify in natural language the exact data type.
- For each kind of functionality, specify in natural language the inputs and outputs and their exact data types and the properties of the intended output.
In addition to details about individual classes, write a natural language description of how the classes interact, describing their connectors. Are they communicating with events, function calls, timers, or other kinds of mechanisms? If it helps clarity, create diagrams to specify these interactions.
Remember that the purpose of this document you’re writing is not to satisfy the instructors. It’s intended to help you organize, plan, and streamline your Gitlet implementation, so focus on writing a document that’s useful to you.
Checkoff: Design Review
The purpose of this design review is to help provide feedback on your project’s architecture early on in the design process. These reviews serve several purposes:
- To catch design errors early, before you spend a lot of time debugging.
- To give you an opportunity to explain and defend your approach (this is an important skill to learn as software engineers).
- To provide an opportuntity to assess your understanding of the project.
Since the completed design document for Gitlet isn’t due until Monday, it’s okay if your group hasn’t nailed down all the details. Make sure you’ve made enough progress to be able to describe the high-level organization of the program though in order to have a productive review.
Then, prepare a questionnaire about your project that you’d like to ask your lab TA about. A few ideas might include asking your design reviewer how they might implement a particularly case in the spec based on the architecture laid out in your design. Or, point out more generally where the design might break down while implementing certain features required by the spec.
The idea is to really put the reviewer in your shoes and study what kind of assertions or assumptions the reviewer needs to make in order to complete the task.
Once you’ve made a bit of progress and all members of your super-group understand what’s expected, raise your hand and a lab TA will ask you a few questions about your design and offer feedback. Feel free to ask your questions throughout the process; the checkoff isn’t meant to be rigidly structured, though your TA will also make sure to leave some time at the end in case you have any final thoughts or concerns.
The lab TA, upon completion of the lab checkoff, will tell you what to put into the magic word file in order to pass the autograder. If there’s a wait, feel free to move on until your group is called.
Delegation
A lot of the work above can be delegated to individual teammates. Assign responsibilities to ensure the work gets done on time.
While you’re producing a document, the real goal of architecture is to make sure everyone on your team has a consistent, detailed understanding of the architecture. If they don’t, you’ll end up with a ball of mud. To test this, quiz each other on the architecture you have planned: can each of you explain it in detail? If not, keep explaining it to each other until you have the same understanding in your heads and in your document.
Read about how to Schedule from Andrew Ko.
Submit your work-in-progress design document to Gradescope as a PDF. It doesn’t need to be complete, but we expect to see some of the architecture and delegation before the final review on Monday. Grades for this won’t be processed until a bit after the lab is due.
Productivity
When it comes to actually implementing the project, two reads that offer helpful perspective are Productivity and Program Comprehension by Andrew Ko.
These aren’t required readings, but becoming more productive will help immensely with the implementation of the project. For large programs in particular, we’ve also found that pair programming is actually the most effective for walking through logic and ensuring that all cases and scenarios are accounted-for. One of the advantages of working together in-person as part of working meetings is that all members of the team are readily available to assist in answering questions and help solve particularly tricky implementation challenges.
- Writing the code together.
- There are many styles for writing code together, but they mostly involve two programmers sharing a single computer. We suggest a pair programming approach where one person types the code while the other person checks their work as they go along. Partners then switch off every so-often. This method is especially helpful when working on a complex problem with many interacting components: the ‘navigator’ can help reduce the cognitive load on the ‘driver’ and catch any painful bugs before they cause problems.
The Collaboration Guide also discusses this idea in greater detail, as well as other strategies.
Recap
The fundamentals always apply:
- Crisp abstractions
- Clear separation of concerns
- Balanced distribution of responsibilities
- Simplicity
—David Parnas
Deliverables
To receive full credit for completing this lab, make sure that you’ve:
- Completed the lab checkoff and submit the magic word to the Gradescope assessment.
- Complete the self-reflection linked in the Gradescope assessment.
- Submit your super-group’s work-in-progress design document to Gradescope.
Acknowledgements
Much of this lab is adapted from works by David L. Parnas, from his talk on Software Aging and his collected papers found in Software Fundamentals.
The exercises are largely adapted from Andrew Ko’s Info 461 course on Cooperative Software Design.
A full list of references and sources appears below in no particular order.
- Andrew Ko’s Info 461 course on Cooperative Software Design
- Björn Hartmann’s CS 160 course (at UC Berkeley!) on User Interfaces
- Jesse Watson on The Hard Thing about Software Development
- David Parnas on Software Aging, and Software Fundamentals: Collected Papers by David L. Parnas
- Software Engineering: Barry W. Boehm’s Lifetime Contributions to Software Development, Management, and Research
- Edsger W. Dijkstra On the Cruelty of Really Teaching Computer Science
- Grady Booch on the History of Software Engineering
- Carl Landwehr, et al. on Software Systems Engineering programmes a capability approach