
Setup #
When I run the tests, I see big red text that says “WARNING: A terminally deprecated method in java.lang.System has been called”, and something about “setSecurityManager”. #
You can safely ignore the four lines:
WARNING: A terminally deprecated method in java.lang.System has been called
WARNING: System::setSecurityManager has been called by <CLASS> (file:...)
WARNING: Please consider reporting this to the maintainers of <CLASS>
WARNING: System::setSecurityManager will be removed in a future release
These four lines are unfortunately unavoidable locally. You can ignore them. They, alone, are not an error.
I can’t run the tests. I’m getting an UnsupportedOperationException. #
This is because you’re (a) running with Java 18 (this is fine), and (b) not using the run configuration distributed. The run configuration includes a flag that allows the tests to run on Java 18. Follow the instructions in the spec to ensure that your run configuration template exists and is correct.
I can’t run the tests. I see something about “Non-final static field” and “disallowed type”, but I don’t know what that means. #
Because of the nature of our test suite, we’ve opted to prohibit usage of any nontrivial (mutable) static fields. With an appropriate program structure, you should not need to use any static fields that are not constants.
Reasoning: Since the test suites essentially run gitlet.Main.main, any static
state is persisted between commands. This is contrary to the behavior we would
usually observe, which is that the program would start anew, reinitializing
all static variables. It isn’t possible to reset all variables to a clean state
on-demand, so we simply opt to prohibit them. Static fields that are not
constants often indicate mutable global state, which is a pattern that
tends to be difficult to reason about.
- Wait, but I wrote my program to use static variables. I need to use global state!
- Try shifting your view of “global”. In particular, many of the fields that you
are probably using as mutable static fields would make more sense
as instance variables of the
Repositoryclass. Try reframing your code in terms of instance variables and methods ofRepository.
I can’t run the tests. I see something like “Test ignored”. #
From the spec: “Tests fail with “This test is not being run in the testing directory. Please see the spec for information on how to fix this.”
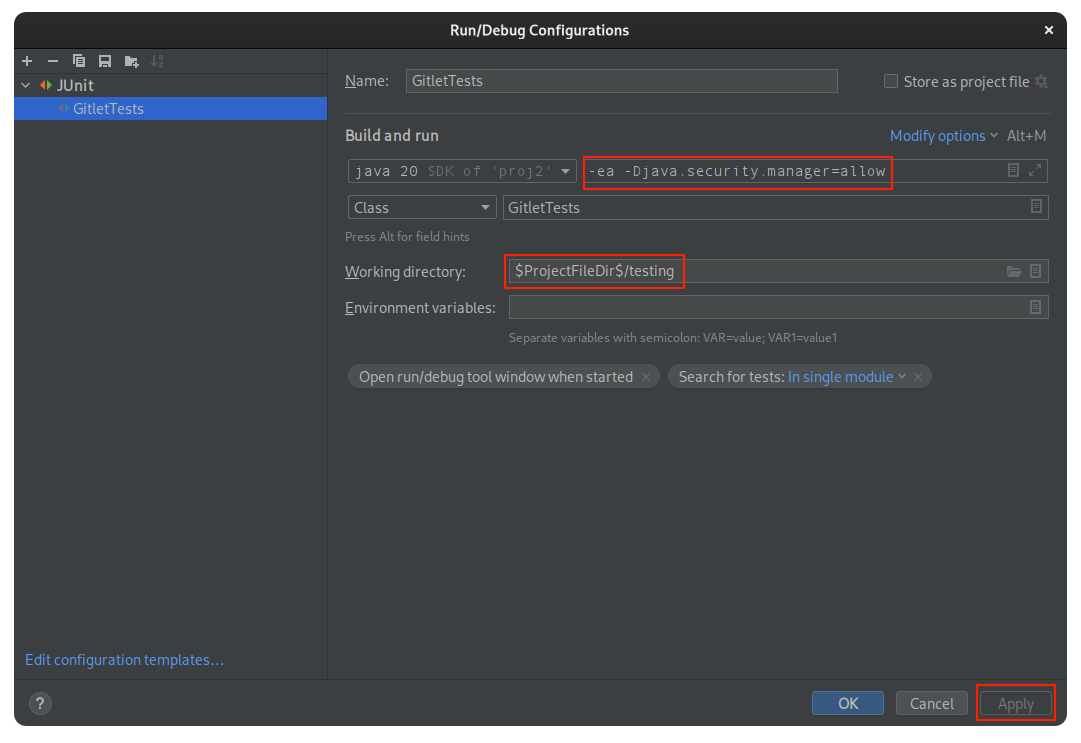
To fix: Your JUnit configs are probably messed up. Delete all your existing run configurations by clicking “Run > Edit Configurations”, and clicking the minus. Then, ensure that .idea/runConfigurations contains a file named _template__of_JUnit.xml, with contents: //omitted”
Make sure to also type the information in the red boxes into your run configuration:
Getting Started (Design Doc) #
First, go watch the (excellent) Gitlet lecture!
The remaining pieces of this section are under construction.
Miscellanea #
What’s a MalformedInputException? #
This occurs when we try to check file contents, but you’ve written a
serialized Java object to the file. Even if the Java object is a String,
Java will write additional information that isn’t readable text. When we try to
read the file to compare it, Java can’t parse the file into a String!
If you’re writing contents to a file, make sure to use the appropriate method
writeContents.
I’m getting an error that I “cannot overwrite directory” #
This message comes from the Utils class when you try to use writeContents or
writeObject on a file that is a pointer to a directory.
I’m getting the error “must be a normal file” #
You are getting this error from readContents because either:
- The file does not exist
- The file is a directory
My sha1 is different before and after I serialize my objects – why? #
There’s a few different reasons for this, but the fundamental issue is that
the object that is read is “different” from the object that was originally
written. This appears often when feeding HashMaps to sha1 (usually as
an instance field of your Commit class).
HashMaps don’t have a guaranteed order, so the order of elements before and
after serialization could be different. Additionally, HashMaps have internal
private fields that get serialized… and also transient fields that don’t. So
the transient fields have different values before serialization, and after
being read, causing different byte-level representations, which causes
different hashes.
We recommend either using TreeMaps, or being careful about how you compute
and use your sha1 hash codes.
How do I get back an object from a sha1? #
Inherently, there’s no way to go from a sha1 id back to an object, since
hashing is a one-way process. To be able to get back the object later, you
would need to serialize the object in a known location, possibly using
the sha1 id in the filename.
I fail the tests when I run them regularly, but pass them when I use the debugger? They also work correctly when I use the command line. #
Why do my tests only pass sometimes on the grader? #
This is usually due to an insufficient SHA-1. When we run the tests “regularly”, they go fast – and it’s very likely that the timestamp will be the same to the second. If your SHA-1 (for blobs, commits, or otherwise), will be the same for different objects that have the same timestamp, this will cause problems.
For commits, make sure that your commit hash calculation includes all the necessary information detailed in the spec.
I’m passing my tests locally but failing on the autograder. #
There’s a few reasons, and we’ll add to the list below as we discover more:
- Windows and Mac are not case-sensitive, so
file.txtandFILE.txtare the same file. However, the autograder is case-sensitive. Make sure you use consistent names for files. We strongly recommend using constants instead of typing the filename everywhere, to reduce the possibility of typos. - If you use
File::listFiles, this does NOT guarantee that the returned files are in alphabetical order. While it may work on your local computer, it is much less likely to work on the autograder. We strongly recommend using theUtils.listPlainFilenamesInmethod instead.
Commands #
init #
add #
commit #
restore #
log #
I finished my log command, but it’s telling me that my output is correct even though I printed everything! #
The format that you print the information has to be exactly the format that
we expect in the spec. In particular, your date / timestamp format must be
exactly correct. Make sure that your timestamps are printed in exactly the
format Date: Thu Nov 9 20:00:05 2017 -0800.
rm #
What is the difference between deleting a file (command-line rm) and gitlet rm? #
When you manually delete a file without using Gitlet, whether using the terminal or GUI, Gitlet does not do anything yet. It doesn’t know anything until a Gitlet command is run, at which point it should re-check the state of the working directory to see that the file has been deleted.
In this case, after I run rm f.txt to delete f.txt, I would still need to
run a Gitlet command. such as java gitlet.Main rm f.txt to take into account
the deletion.
global-log #
find #
I fail test25 when I run the test, but pass it when I use the debugger or run it from the command line. #
See above.
status #
In test15 (test 15), why is f.txt not Staged or Removed in the last status? #
The current contents of f.txt are “This is a wug.” (wug.txt), and it
was staged for removal as a result of java gitlet.Main rm f.txt.
When we run java gitlet.Main add f.txt, two things happen, per the
add specification):
If the current working version of the file is identical to the version in the current commit, do not stage it to be added, and remove it from the staging area if it is already there (as can happen when a file is changed, added, and then changed back to it’s original version).
So f.txt is not Staged, because its contents are identical to the version in
the current commit.
“The file will no longer be staged for removal (see
gitlet rm), if it was at the time of the command.”
We also remove f.txt from the removal stage.
I’m failing the status output, but I’m not sure what’s different. #
Some things that could be the case are:
- Remember to print everything in lexicographic (alphabetical order). This applies to branch names and filenames! See above for more information.
- Even if you don’t do the optional status portions, you still need to print those headings (just leave those sections empty).
branch #
Would we switch to the new branch after we run branch command? #
Initially, our current branch is main. We only change our current branch when
we run the switch command. Let’s say we do git branch b1, we create one
more branch pointing to the most recent commit of our current branch main.
However, the current branch is still main. When we do git switch b1, now
our current branch will switch to b1.
rm-branch #
switch #
What does the “untracked file” failure case for switch mean? #
If a working file is untracked in the current branch and would be overwritten by the switch, print
There is an untracked file in the way; delete it, or add and commit it first.
A “working file” is a file that is present in the CWD. When a file is “untracked in the current branch”, it is not present in the head commit of that branch. Remember that a file may be tracked in the head commit even if was not changed in that commit, since a commit by default inherits the parent commit’s tracked files. When a file would be “overwritten by the “, we are saying that the target branch’s head commit contains that file. We won’t test the case where the contents in the target commit are identical, so you can simply fail if the target branch contains the file.
In other cases, such as when we have a tracked working file that would be overwritten by the checkout, there is no error, even when the file has uncommitted changes. Additionally, when we have an untracked file that would not be overwritten by the checkout, there is no error.
reset #
What does the “untracked file” failure case for reset mean? #
See
checkout case 3,
as the general idea of the failure case is the same (hint, hint). Instead of a
target branch’s head commit, we have a target commit.
merge #
I’m having trouble visualizing the merge tests. #
We’ve found diagrams from a previous year illustrating the following tests:
- Test 33 (
test33_mergeNoConflicts) - Test 34 (
test34_mergeConflicts) - Test 35 (
test35_mergeRmConflicts) - Test 36a (
test36_mergeParent2) - Test 40 (
test40_specialMergeCases) - Test 44 (
test44_baiMerge)
These diagrams are located in this Google Drive link. You will need to use your Berkeley account to access these files.
For test 36, why does the test expect that f.txt exists? #
Why is the split point for test 36 not the initial commit? #
When looking for the split point, we don’t just follow commit parents – we also follow merge parents. Therefore, as you can see in the merge case diagram for test 36, the split point is actually the commit that branch C1 is on!